|
 посвящается памяти Заратустры, Кухулина и св. Патрика посвящается памяти Заратустры, Кухулина и св. Патрика
10 частей сериала о применении ПК в сравнительной лингвистике соответствуют числу рассматривавшихся исторических индоевропейских языков (точнее, семейств языков). Это не задумывалось нарочно, и точка была бы символичной; однако на равных с ними фигурировала и «новая реконструкция», поэтому часть №11 тоже уместна, тем более что в ней всего два замечания.
1. Первое замечание относится к использованному в сериале математическому аппарату трехзначной логики и имеет общее значение, не связанное с лингвистической спецификой.
Фонетические системы в исследовании представлены как наборы трехзначных параметров, поэтому каждый объект (язык) набор однозначно определяет трехзначную функцию на множестве всех параметров, т.е. его трехзначное подмножество.
Некоторые подробности о трехзначных множествах можно найти на сайте и в статье «Суждение и вычисление: не исключая третье» (PC Magazine RE, №11, 2006), где показано, что понятие «мощности множества» (числа его элементов) единственным способом распространяется с обычных множеств на трехзначные.
Так же, как обычная булева алгебра множеств связана с обычной двузначной логикой предложений, алгебра трехзначных множеств связана с трехзначной логикой. Но если такие операции, как конъюнкция (пересечение) и дизъюнкция (объединение), имеют единственные естественные трехзначные продолжения, то это не так для других, например, для отрицания и импликации (логического следования). В трехзначной логике на роль последней претендуют несколько функций, из которых наиболее известна «импликация Лукасевича». С каждой из импликаций связывается своя функция эквивалентности, поэтому существует «эквивалентность Лукасевича». (Кстати, используемое в трехзначной логике симметричное отрицание иногда также называют именем этого польского логика).
Для сравнения фонетических систем, представленных как трехзначные подмножества, использовалась метрика, равная сумме отклонений по всем (или нескольким) параметрам и известная также как «квартальная» или «метрика почтальона». По ходу работы с трехзначными лингвистическими параметрами и выбранной метрикой я заметил связь между тремя понятиями:
расстояние между трехзначными множествами равно мощности отрицания их эквивалентности по Лукасевичу
(на практике использовалось целочисленное расстояние, равное двукратной мощности, которая может быть дробью со знаменателем 2). Короче выразить эту связь можно, вводя «неэквивалентность (или разность) по Лукасевичу». Формально она продолжает известную формулу для обычных множеств
d(A,B) = |(A≡B)'|,
где отрицание (дополнение) и эквивалентность не имеют вариантов, а
(A≡B)' = (A/\B')\/(A'/\B)
называется «симметрической разностью» множеств A, B. Однако трехзначное обобщение этой формулы не сводится к замене операций в правой части их трехзначными аналогами, которые в итоге не приводят к метрике. Здесь требуются модальные функции трехзначной логики; подробнее о них см. в указанных источниках.
Обнаруженная связь метрических и логических понятий не дает каких-либо вычислительных преимуществ на обычных ПК с их двоичной элементной базой и арифметикой. Пока она важнее в методологическом плане, поскольку применение трех значений для фонетических параметров, как и метрики суммарных различий, было в основном технической процедурой и не подразумевало их логической интерпретации.
2. Второе замечание относится к содержательной стороне дела и вытекает из особенностей примененного аппарата.
В ч. №10 шла речь о фонетических параметрах C21, C31, O2, S23, порождающих все другие, и особом свойстве пары O2, S23 – она единственная принимает 8 наборов своих значений из 9 возможных. Там же говорилось о том, что отсутствие 9-го набора (O2=1, S23=0) вызвано, вероятно, случайностью – небольшим числом достаточно изученных индоевропейских языков (семейств).
Обнаружение языка с такими значениями подтвердило бы независимость параметров O2, S23 и тем самым их базисный характер; кроме того, оно имело бы и другие любопытные следствия.
Забудем на время о параметре C31, важном только для различения гипотетической «новой реконструкции» (Н) – тройка C21, O2, S23 полностью характеризует все исторические языки. Чтобы не рисовать трехмерные чертежи, заметим, что куб, образуемый этими тремя параметрами, состоит из девятиточечных плоскостей. В частности, средняя плоскость O2=0 содержит только языки «древнейшего блока» – греческий, латинский, хеттского, арийский (индоиранский). Трем значениям параметра C21 соответствуют три параллельные плоскости параметров O2, S23. Если на этих плоскостях отметить все 10 исторических языков, то получится следующее (O2 – абсцисса, S23 – ордината):
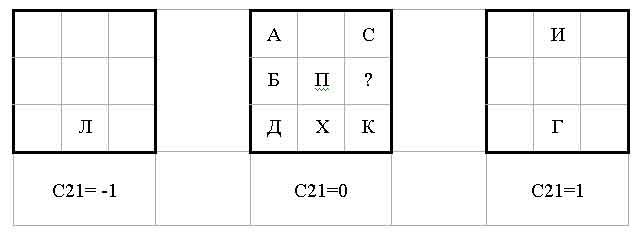
На среднем чертеже (C21=0) знаком ? отмечена точка O2=1, S23=0 отсутствующего 9-го набора; при ее добавлении эта плоскость, а с ней и весь куб C21*O2*S23 будет симметричным относительно плоскости O2=0: если в кубе есть точка C21, O2, S23, то есть и C21, -O2, S23 (симметрия сохранится и для 4-мерного куба C21*C31*O2*S23, содержащего «новую реконструкцию»).
Эта еще одна гипотетическая фонетическая система, симметричная балтийской (Б), находится между иранской (П), кельтской (К) и славянской (С) и должна стадиально предшествовать последней: славянский язык имеет достоверные лексические заимствования из иранского и кельтского, тогда как другие языки с такими связями вряд ли известны. Возможно, эти связи относятся ко времени возникновения «ирано-кельтской» фонетической системы, развившейся затем в славянскую.
Наконец, еще один содержательный факт, вытекающий из, казалось бы, формально-логических выкладок. Фонетический смысл параметра O2 – изменение тембра модифицированного гласного, возникающего из основного («краткого») гласного тембра «О». O2=0 означает сохранение тембра, что характерно для языков «древнейшего блока». Однако в хеттском такой тембр просто неизвестен, в арийском он вторичен, в латинском алфавите модификация («продление») соответствующего гласного не имеет специального обозначения. И лишь в позднем греческом письме возникает соответствующая буква (омега, т.е. «О большая»), занимая последнее место в алфавите.
Эти факты заставляют полагать, что образование фонологического тембра «О» и тем более его модификация были процессами поздними, протекавшими в самостоятельных индоевропейских языках, но не в гипотетическом общеиндоевропейском.
Автор: Александр Рябцев
|
